Five principles for community altmetrics data
I presented these ideas at the altmetrics18 workshop. You can read a slightly more formal version of this blog post here.
These five principles are my answer to some of the difficulties and problems I have observed in the past couple of years. In that time I have been collecting the kind of data that altmetrics are built from, and talking and working with researchers. Altmetrics data is derived from the community. I think that community should continue to be at the heart of every step.
Others have written about the rights and wrongs of altmetrics for signalling and assessing knowledge. In the NISO Altmetrics Code of Conduct work we discussed transparency and codes of conduct for data providers. But these big-picture ideas must be supported by specific, actionable principles.
Five principles
- Metrics should be decoupled from the underlying data that they are derived from.
- Underlying data should be open, available data sets.
- Underlying data sets should reflect the diversity of the behaviour being observed. Metrics (and other derivatives) should reflect the diversity of audiences.
- The software that collects the underlying data should be open source. Both the intended behaviour and the actual behaviour of those systems should also be open.
- Community contributions and feedback should be integral to the operation and collection of the data.
These are the guiding principles that I have arrived at whilst building Crossref Event Data, but they are not specific or exclusive to that project. They represent my personal views, not necessarily those of Crossref. I’m not claiming that they’re novel, or that any particular data provider does or doesn’t do them. I would love to see them adopted by all, though.
Background
Feedback loop
The field of altmetrics is pleasingly circular. Like bibliometrics, altmetrics observes the behaviour of the scholarly community and reports back to that community on its own behaviour. Where bibliometrics looks at citations, altmetrics looks at some of the more unconventional alternative places where people may be interacting with the literature. That could be discussions on blogs, recommendations or likes on social media. By its very nature, altmetrics seeks the novel and unconventional, and the job is never complete. The community will always find new ways to interact with the literature and altmetrics should always seek to understand them. As these methods become recognised and mainstream, we will, by definition, continue to see new “non-traditional” venues and styles of interaction. Our best chance at keeping up with the community lies in the community.
We are lucky to have an active and insightful group of altmetrics researchers. The recent paper from Zahedi and Costas (2018) is a nice example of this. It analyses a handful of altmetrics providers, including an early beta version of the service I’ve been designing and building, Crossref Event Data. I’ve published my reflections in a blog post. Their study is particularly interesting as it sets out some of the problems they had collecting, understanding and hypothesising reasons for the behaviour of the services under discussion.
No new gods
Scholarly publishing is entering a new, increasingly democratic, age. The old gods of traditional journals publishing are facing challenges from preprints, open peer reviews, open data and open access publishing. Existing metadata services should embrace this. Crossref, for example, now allows registration and assignment of DOIs to preprints and peer reviews.
It would not do well for altmetrics data providers to follow any path that leads to to another ‘us and them’ situation. We should be part of the community, not external observers and external sources of truth. There are objective truths (a webpage either did or didn’t cite a given article, although there’s nuance to this), but the pursuit of that truth will always be incomplete, should be open to challenge, and can always benefit from being situated in that community.
Metrics should not be the target
We have been collecting traditional citations long before H-index and Impact Factor. The point of citations is not metrics: whilst they have a great number of uses, first and foremost they are about tracking the provenance of knowledge. They can be used to create metrics, (although there are plenty of concerns in scholarly publishing around gaming, citation rings, salami-slicing), but metrics are not the ultimate aim.
Web mentions (e.g. a blog post or tweet that references an article) are similar to citations. They are a new way that people can interact with the literature beyond traditional scholarly publishing. But each web mention has value, in the same way that each citation has value. We should not set out to treat web mentions as bulk commodities to be collected and counted. Rather, we should seek to understand what each data point means, and what they mean together in aggregate.
Just as existing metadata pipelines seek to represent citations between articles as first-class objects, pipelines for recording web mentions should treat these web mentions as individual data points.
Principles in depth
1 — Metrics should be decoupled from the underlying data that they are derived from.
Problem: Metrics can be provided as black boxes. Researchers can't always tell how they were created.
Solution: The input from which metrics are derived should be clearly delineated in a separate dataset. Metrics can be provided as one or more layers on top. The metric can describe precisely which parts of the dataset contributed toward it.
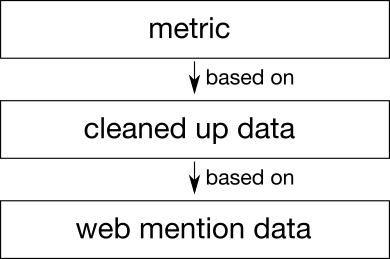
Metrics are based on underlying data. Collection that data is one thing, deriving outputs from it is another.
Uncertainty
On a number of occasions Zahedi and Costas had to guess as the behaviour of a system. For example of Altmetric.com:
… which implies that the count won’t decrease but wouldn’t be possible to fully recreate it …
And of Crossref Event Data:
Also the recent start of CrossRef (sic) ED may imply that they started to collect tweets…
There should never be any uncertainty in how a particular metric was produced. The parameters of the input data for a given derivative should be clearly indicated, and that data should be open. I discuss this point specifically in my blog post responding to the paper.
Some research studies have used a metric score as the independent variable in their research. This might be fine if we want to study the effect of the metric. But if we use the metric as a proxy for something else (e.g. the attention an article is gaining on social media) then we should be crystal clear about the relationship between the metric score and the original empirical observations that were made.
Untidy world
A typical underlying data set is a series of observations. An example datapoint might assert that a given tweet cited a given article. Other features, such as timing, provenance and other supporting information, could also be included. Event Data chooses to express this as a stream of Events that can be queried over time, but there may be other suitable data models.
The web is messy, so the underlying data could be just as messy. The same blog post may have been reported at two URLs, meaning that there are two data points that should perhaps be deduplicated into one. Or an article may be represented by two identifiers in Wikipedia (e.g. DOI and PMID) and should similarly be deduplicated.
Altmetrics sets itself up in opposition to the (supposedly) tidy world of conventional journals publishing where all the reference lists are (in theory) carefully curated and linked. The community of people who work with this data is dealing with a fundamentally messy world of data, and they should not be artificially separated from that. Hopefully open discussions founded on open data will advance the sum of knowledge.
Separation of concerns
Different questions have different requirements on the data. Some research questions may require precise, if messy data. Some end-user applications may call for a more polished single number. Some people want something in between.
One solution to this kind of problem is a principle called separation of concerns. The metrics pipeline could be separated into a number of layers, each layer having one job. For example:
- a layer that collects underlying data layer would focus on the accurate collection and representation of data
- a layer above that might de-duplicate data points
- a layer above that might catch spam or identify patterns
- a layer above that might create metrics for end-user consumption
Dimensions of difficulty
Every data source poses its own problems, and these can occur on different axes. For example Twitter poses the following problems:
- How do we collect data?
- How do we match article mentions to DOIs?
- How do we decide if each tweet is positive or negative?
- How do we decide if the tweeter is qualified to make a judgment about the article?
- How do we create useful metrics from this?
In combination, these questions can confound each other. We cannot hope to study more than one question at once. The data, and processes, should allow us to insert our test probes long the process, and focus on answering one question at once.
Benefits
Allowing the layers to be completely separate brings multiple benefits:
- We can question the data that goes into a metric before the calculation.
- We can put test data into the metric calculation to see how it works under various circumstances.
- We can create new, experimental, metrics that interpret the same data in a new way.
- Each layer can be made available separately, so the layers above it can be re-implemented or improved.
- Each layer can be subject to individual scrutiny.
2 — Underlying data should be open, available data sets
Altmetrics is a scholary pursuit. There is a growing appreciation for the virtues of backing up scientific research with open data. The collectors, aggregators and providers of altmetrics data should be doing everything they can to enable this style of research.
Problem: There is a general drive in academia to increase the citation of datasets. Without citing a dataset, an altmetrics paper may not be reproducible or falisifable. This motivation is set out in the FAIR Guiding Principles.
Solution: Publish the dataset, give it an open data license.
Problem: If serious funding, tenure or policy decisions are being made based on metrics, the transparency should extend down as far as possible. The more transparency, the better scrutiny those decisions can be given.
Solution: Publish the dataset. If it’s clearly separated from the metric, it’s easy to publish.
By presenting the underlying data as an open dataset, it also means that it can be mixed or compared with other datasets. Allowing other people to take copies of the data and archive it (providing they continue to abide by the terms and conditions, for example, Twitter compliance), also removes a single point of failure.
3 — Underlying data sets should reflect the diversity of the behaviour being observed. Metrics (and other derivatives) should reflect the diversity of audiences.
Problem: There are a lot of people interacting with the literature, and the way they do it can be diverse. We need to capture that diversity. We can’t do this alone.
Solution: We can do our best to monitor as may different places as possible but there is always implicit bias. By encouraging a plurality of data sources and providers we can try to address this a little.
Problem: Technology, including social media and altmetrics are created for specific audiences. They might incorporate cultural biases, which might put people at a disadvantage.
Solution: Ensure that the underlying data is open so that different metrics can be created for different audiences.
There is also a diversity of users of these outputs. At the 2017 Altmetrics Conference there was an active discussion about ‘feminist metrics’, which resulted in a “Feminist Approaches to Altmetrics” investigation at the do-a-thon.
When altmetrics can be used for serious tenure and funding decision this places pressure on academics, especially early career researchers, to engage on the Internet. To take one example, when women are more likely to be exposed to harassment on the Internet, this places them in harms way or at a serious career disadvantage.
A one-size-fits-all solution does not serve the entire community. It should be possible to use different methods suitable to different communities, and to experiment with new ones.
4 — The software that collect observation data should be open source. Both the intended behaviour and the actual behaviour of those systems should also be open.
Problem: It’s not always clear how data was collected. Different providers monitor the same source, but they way they do it can vary wildly.
Solution: The software that collects this data can be open source. This means that researchers can look at the source code and understand exactly how the data collection is intended to work.
Problem: The Internet is unreliable and heterogeneous. Things don’t always work, data can be missing, or software can break. Even if you know how the software is meant to work, you don’t know if it actually happened.
Solution: Data should be backed up by provenance information and evidence.
Problem: Software changes over time. Today’s source code isn’t much use when talking about data collected a year ago.
Solution: Include source code and version information with each data point in the underlying data set.
Problem: It’s impossible to document every facet of behaviour in advance.
Solution: In addition to describing what should happen, describe what actually happened when collecting a given dataset.
We should not expect researchers to be computer programmers, but it should be possible to explain how the algorithms work and demonstrate that the explanation is accurate. Every data point can include a link back to the software version that produced it, so they can examine how it worked.
Including logs about every decision point that was made and every action taken allows researchers to explain why a given data point was collected (or to explain the absence of a missing point).
5 — Community contributions and feedback should be integral to the operation and collection of the data.
Problem: There are always ways that people are interact with literature. No one organisation can hope to keep up.
Solution: Include the community right in the process and encourage them to contribute knowledge.
Problem: When you choose where to look you make a cultural decision.
Solution: Involve the community in decisions, ask for their feedback on choices of sources. Where it is not possible to collect a certain kind of data, have an open discussion about the difficulties, and reasons it is difficult. Researchers may be able to advance what’s possible, or to collect data themselves.
Altmetrics, as indicated by the name, is predicated on identifying alternative ways and places in which people are interacting with the scholarly literature. We cannot hope to do this by existing outside the community. Instead, we should be embedded in there. By providing open data, source code and pipelines we can do as much as possible to demonstrate open-ness and facilitate inputs from the community.
Input can come in at least four forms:
- Ideas about where to look for interaction.
- Feedback about the weaknesses of the data and suggestions for improvement.
- Data collected by members of the scholarly community can be fed into open pipelines so everyone can benefit from it.
- Contributions to open source projects.
When we make the underlying observation data open and open up the source code, we remove barriers that separate us from the altmetrics community, and the broader scholarly community. When the community feels ownership of the service, they will be happier to contribute their feedback and their data.
By seeking data from more diverse places, we enable people familiar with those places to bridge the gap and help bring that information to a wider audience. In practice this means asking the community for ideas about new sources and maybe even allowing them to collect observation data and contribute it back to the community.
Community ownership means that people regard the service as a two-way-street, and integrate it into their workflows.
Counter-arguments
Security by obscurity
Challenge: If algorithms are open, they can be gamed more easily. It’s better if there’s a secret clean-up process to counteract gaming.
Response: As soon as social media engagement was incentivised for progression in academia, the clock started ticking on Goodhart’s Law.
These are issues that affect the community, to be discussed by the community. If spammers are identified, it’s much better that they are identified in an open manner, so everyone knows.
A judgment is always made in a cultural context. Given that altmetrics seek to capture diversity, there are questions to be asked here. By analogy Beal’s List, an attempt to classify publishers considered ‘predatory’ has sometimes been controversial in its judgments. We should avoid creating new gatekeepers and unilateral decision-makers.
Open processes increases the opportunity for a right-of-reply. A decision made about the validity of a given data point can be challenged if it is done in public.
“Let the community decide” is a cop-out
Challenge: The community needs to depend on a qualified arbiter to make decisions of quality. This stuff is hard and we need experts.
Response: We do need experts, and those experts exist out in the altmetrics and bibliometrics communities. We should empower as many researchers as possible to create their own interpretations of the data.
Allowing the underlying data to exist out there doesn’t stop any authoritative expert producing their own metrics.
Open data undermines commercial products
Challenge: If everything’s open, who’s going to pay for all this?
Response: There is scope for value-add in professional services or the creation of metrics for specific audiences. Releasing the underlying data and source code openly doesn’t mean releasing the whole product.
There are parallels in the open source software community, where the source code is free but value-add services are sold to customers.
Ultimately, this comes down to the same questions about open and closed references and infrastructure in journals publishing.
Web citations are different to scholarly citations so they shouldn’t be treated the same way.
Challenge: In journals publishing you always know all of the journals that exist and, in theory, you could get perfect coverage of all citations. You can’t hope to capture all citations from the web. Therefore you shouldn’t try to treat them the same.
Response: You don’t necessarily know all journals. The continued long tail of Crossref membership is testament to that. In the same way that small scholarly publishers are continuing to enter the ecosystem, we will discover more and more places where people are interacting with the literature on the web.
We should be on guard against commoditising web-citations in bulk, just as with traditional citation-based metrics. There is a place both for individual citations and total-based metrics, both in journals publishing and altmetrics.
Article citations are well-understood and uniform. Web citations are messy, unclear and unreliable.
Challenge: Scholarly authors stick to specific conventions (paper layout, citation style etc). The reference list of an article is a carefully constructed structuring of information. DOIs mentioned in blog posts don’t mean the same thing as citations.
Response: The shift toward online platforms for discussion indicates a shift in the way that academics want to discuss their subject matter. We should not constrain new forms of expression so they fit with the old ones. Neither should we constrain the way that we represent new forms of citation.
Furthermore, citations in traditional journals can be negative or positive and that’s not traditionally recorded in a reference list. Reference lists aren’t perfect as it is.
On top of this, journals publishing is sometimes messier than people think. There are plenty of people trying to extract citations from the ’traditional’ literature using text and data mining, including the publishers! Citation databases are sometimes incomplete or unavailable. The situation is not so different.
Open data enables harassment
Challenge: By collecting data about human interactions, we enable harassment.
Response: Only public data should be collected. So, I am not advocate exposing more data. However it cannot be denied that surfacing it and making it searchable could cause problems though. This is a wider problem that applies to journals publishing too.
We must be vigilant and also flexible in our methodology. Keep the conversation going about data pipelines and the behaviour they facilitate, promote and potentially suppress. By using open source software and behaviour we can do our best to provide systems that can be reasoned about and adjusted. Where there is bias, we can at least try to quantify it, even if it can’t be eradicated.
Twitter, which is a special case but comprises a large chunk of interaction, has very strict rules about how the data can be used, and how user intent should be honoured.
Limiting to open data limits the research you can do.
Challenge: Not all interactions that we might want to study are done in public. By limiting ourselves to open datasets, we exclude those private conversations.
Response: It’s true, there are some kinds of interaction we can’t study. That’s up to the researchers.
Where do you draw the line?
Challenge: There’s no such thing as “raw data”. You can claim that your dataset of underlying observations doesn’t “interpret the data”, but the very act of choosing where to look introduces bias. You have to draw a line somewhere, and you’re just choosing to draw it in a different place to established altmetrics providers.
Response: It’s true that strictly there’s no such thing as “no interpretation”. The second principle attempts to draw a line between “underlying data set” and “metric”. I think that the process of collecting data and representing it in a common format has a clear boundary. And the process of de-duplication, weighting, quantifying and aggregating data points to create a metric is similarly self-contained. After all, we are writing a finite amount of software to do this, so finite boundaries do exist.
If the processing is formed of layers, intermediary levels could classify and combine data, progressively cleaning it up for a given purpose. Each of these layers of datasets could represent a level of granularity, accuracy or abstraction, effectively drawing a number of intermediary lines between ‘underlying data’ and ‘metric’.
There is always some interplay between the layers: the analysis may show, for example, that a given data point is anomalous, or that more data should be collected. It is possible to design a system so that subsystems can talk to each other while remaining distinct.
Underlying data is very difficult to use. It’s better that someone clears it up.
Challenge: Underlying data is messy, spammy, and difficult to use.
Solution: There are researchers out there who can work with it. Let them.
The solution to difficult-to-work-with data is to clean it up. This doesn’t have to be a destructive process, though. You can take an input data set, clean it up, and provide an easier-to-use dataset at a layer above it.
Of course, different people may want to do that differently. By making the data-collection layer as faithful as possible and allowing cleaning up at higher levels, we build the most transparent solution we can.
Further reading
- Open Metrics as Part of Persistent Identifier Infrastructure (Martin Fenner)
- Scientific Attribution Principles (Martin Fenner)
- FAIR Data Principles
- Altmetrics manifesto (Jason Priem, Dario Taraborelli, Paul Groth, Cameron Neylon)
- General discussion of data quality challenges in social media metrics (Zahedi and Costas 2018)
- Some thoughts on Zahedi and Costas (2018) (Joe Wass)
- Cultural Relativism on Wikipedia
- San Francisco Declaration on Research Assessment
More I’ve written:
- Bridging Identifiers
- Event Data as underlying Altmetrics Infrastructure
- You do want to see how it’s made — seeing what goes into altmetrics
What do you think?
I would love to hear what you think, and how the adoption of these principles would help or hinder the work you are doing. What have I missed?